DeepPipeline元素¶
前言¶
DeepPipeline 是一个基于 Dagster 的数据流处理框架,提供了完整的异步和同步执行能力。本文档详细介绍了 DeepPipeline 类的公共接口。
运行数据流¶
构建了一个test_02的数据流(生成模拟订单数据,整理成数据集形式输出每个订单号和金额)
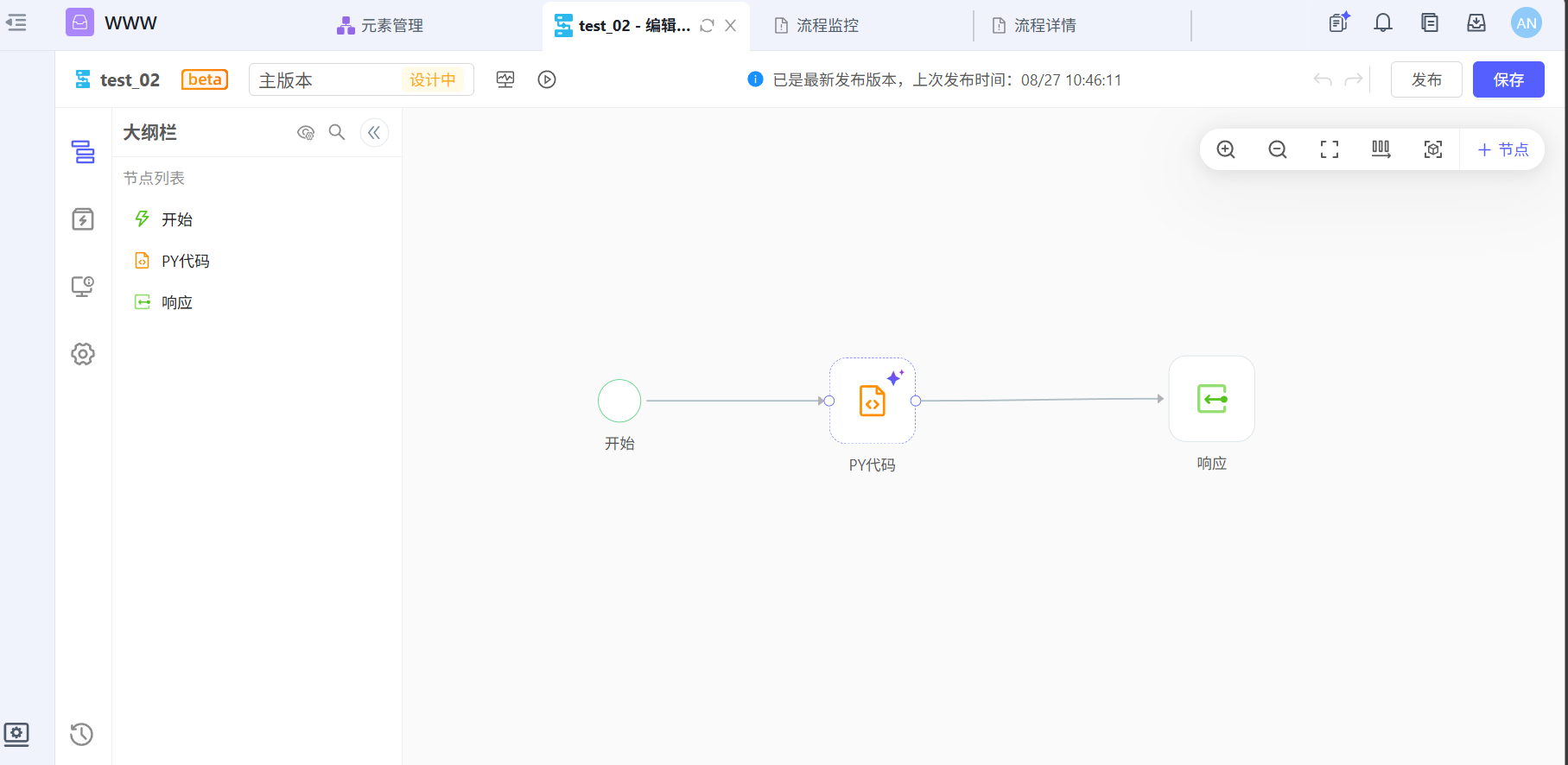
1.获取run_id(run_async)和(run_batch)¶
参考接口文档中的异步启动数据流和批量异步启动数据流获取执行id或者执行id列表。
以异步启动数据流(run_async)为例进行接口使用说明。
参数说明: - parameter (Any) – 执行参数,默认为空对象 - in_process (bool) – 是否在同一个进程执行,默认为 False
返回值: - 执行ID
使用示例:
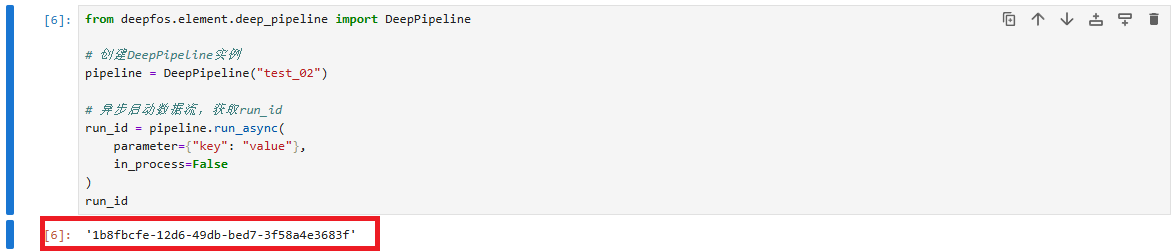
[6]:
from deepfos.element.deep_pipeline import DeepPipeline
# 创建DeepPipeline实例
pipeline = DeepPipeline("test_02")
# 异步启动数据流,获取run_id
run_id = pipeline.run_async(
parameter={"key": "value"},
in_process=False
)
run_id
[6]:
'a89f3e9d-d1bf-4baf-a53a-8bf0c6259e55'
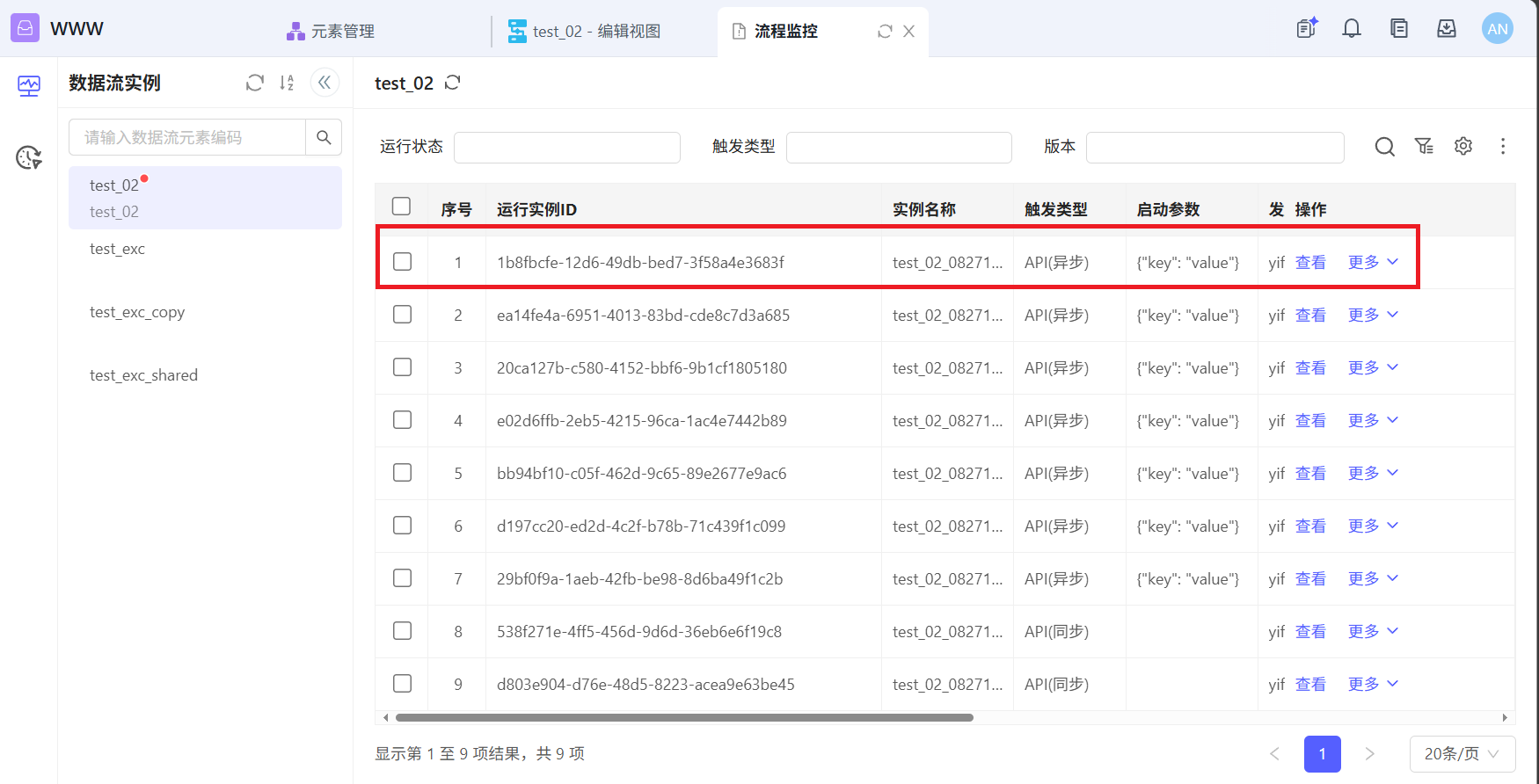
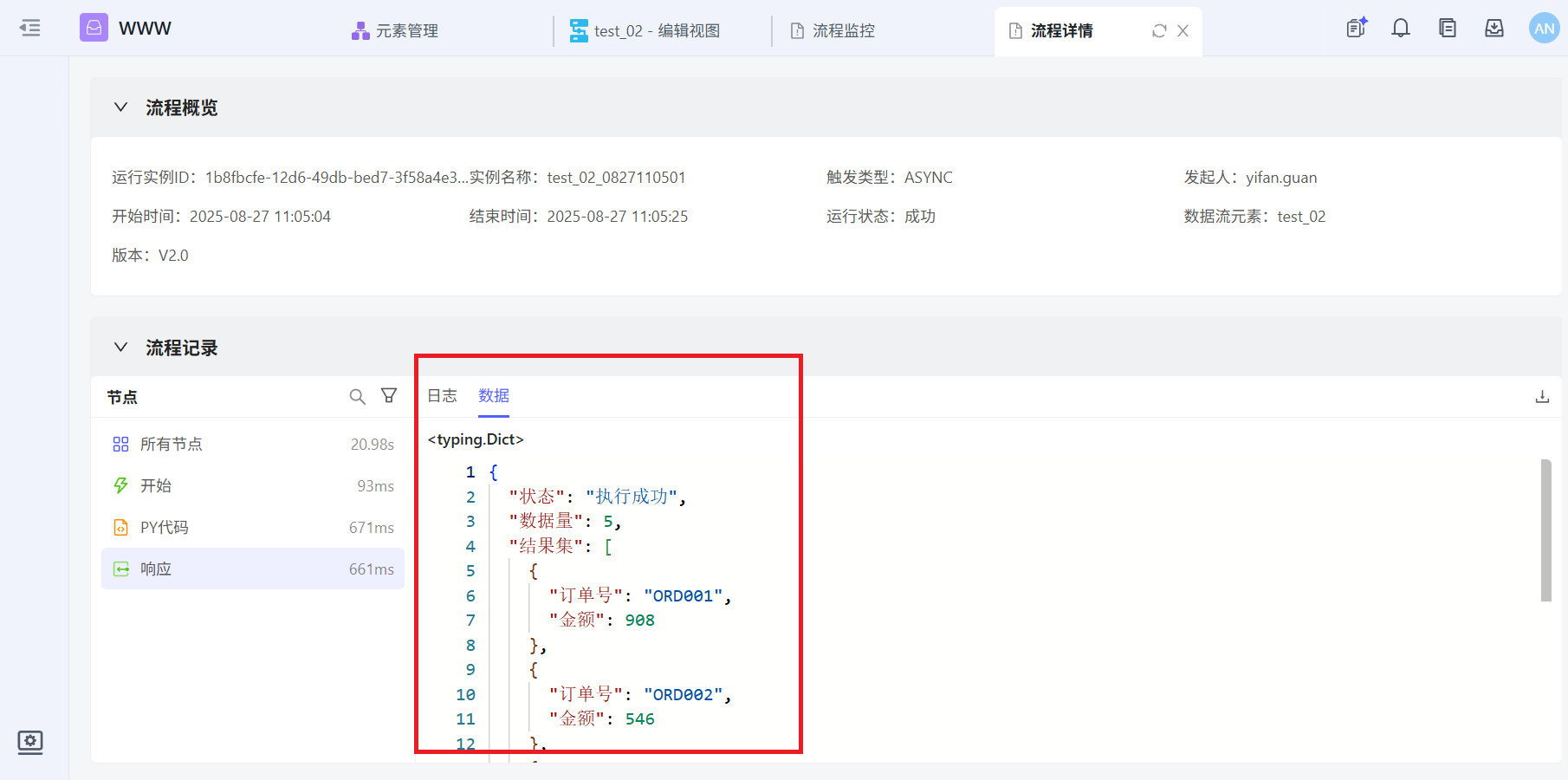
通过接口调用test_02之后返回的run_id与监控中生成的运行实例ID一致
2.通过run_id获取执行结果(result)¶
参考接口文档中的获取异步执行结果,可以通过run_id来获取执行结果。
获取异步执行结果(result)接口使用说明。
参数说明: - run_id (str) – 执行ID(由 run_async 或 run_batch 返回) - timeout (Optional[int]) – 超时时间(秒),可选
返回值: - 执行结果
使用示例:
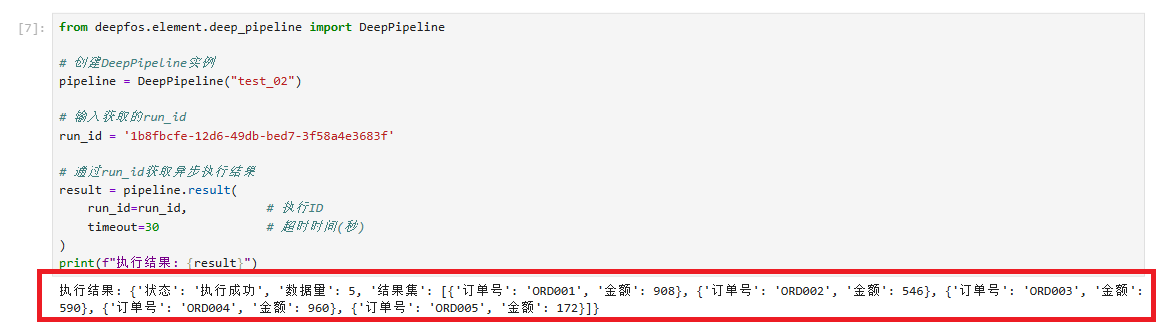
[7]:
from deepfos.element.deep_pipeline import DeepPipeline
# 创建DeepPipeline实例
pipeline = DeepPipeline("test_02")
# 输入获取的run_id
run_id = '1b8fbcfe-12d6-49db-bed7-3f58a4e3683f'
# 通过run_id获取异步执行结果
result = pipeline.result(
run_id=run_id, # 执行ID
# 可以根据实际数据流的复杂程度调整timeout值,建议从60秒开始测试,逐步调整到合适数值。
# 若是简单的数据流可以不需要此参数
# timeout=60 # 超时时间(秒)
)
print(f"执行结果: {result}")
执行结果: {'状态': '执行成功', '数据量': 5, '结果集': [{'订单号': 'ORD001', '金额': 908}, {'订单号': 'ORD002', '金额': 546}, {'订单号': 'ORD003', '金额': 590}, {'订单号': 'ORD004', '金额': 960}, {'订单号': 'ORD005', '金额': 172}]}
通过run_async接口获取的id或者在监控中任意选择一运行实例id,通过result接口获取的执行结果和在监控中查看的执行结果一致。
3.同步直接获取执行结果¶
参考接口文档中的同步启动数据流,可以直接运行数据流获取执行结果。
同步启动数据流(run)接口使用说明。
参数说明: - parameter (Any) – 执行参数,默认为空对象 - timeout (Optional[int]) – 超时时间(秒),可选 - in_process (bool) – 是否在同一个进程执行,默认为 True
返回值: - 执行结果
使用示例:
[5]:
from deepfos.element.deep_pipeline import DeepPipeline
# 创建DeepPipeline实例
pipeline = DeepPipeline("test_02")
# 同步启动数据流
result = pipeline.run(
parameter={"key": "value"}, # 执行参数
in_process=True # 是否在同一个进程执行
# 可以根据实际数据流的复杂程度调整timeout值,建议从60秒开始测试,逐步调整到合适数值。
# 若是简单的数据流可以不需要此参数
# timeout=60 # 超时时间(秒)
)
print(f"执行结果: {result}")
执行结果: {'状态': '执行成功', '数据量': 5, '结果集': [{'订单号': 'ORD001', '金额': 900}, {'订单号': 'ORD002', '金额': 402}, {'订单号': 'ORD003', '金额': 613}, {'订单号': 'ORD004', '金额': 188}, {'订单号': 'ORD005', '金额': 905}]}